운영 환경에서 특정 좌표가 어떤 영역(Polygon)에 포함되는지 확인하는 기능은 위치 기반 서비스에서 흔한 요구사항입니다. 저희 팀에서도 이 기능을 운영하고 있었는데, SPATIAL INDEX를 걸어뒀는데도 쿼리가 예상보다 훨씬 느린 문제를 겪었습니다.
처음엔 단순히 데이터가 많아서 그런 줄 알았는데, 파고 들어가 보니 Soft-Delete된 데이터가 공간 인덱스 안에서 유령처럼 살아남아 매 쿼리마다 불필요한 연산을 일으키고 있었거든요. 오늘은 이 문제를 발견하고 해결한 과정을 공유합니다.
참고: 본문에 등장하는 테이블명, 컬럼명 등은 실제 구현과 다르게 임의로 변경하여 작성했습니다.
1. 문제 상황: 인덱스를 타는데 왜 느릴까?
특정 포인트가 포함된 영역을 찾기 위해 ST_Intersects 함수를 사용하고 있었습니다. 공간 인덱스도 잘 잡혀 있었는데, 응답 속도가 기대에 훨씬 못 미쳤습니다.
- 대상 테이블:
service_zones - 쿼리: 특정
POINT가geom컬럼의 폴리곤 안에 포함되는지 확인 - 증상: 인덱스 레인지 스캔을 수행함에도 CPU 사용량이 치솟고 응답 속도가 저하됨
인덱스를 타고 있는데 느리다? 예전에 SQL 쿼리 튜닝을 하면서도 비슷한 경험을 했었는데, 이번엔 공간 인덱스라 원인이 좀 달랐습니다.
2. 원인 분석: EXPLAIN ANALYZE로 내부 들여다보기
문제의 실체를 파악하기 위해 EXPLAIN ANALYZE를 실행했습니다.
EXPLAIN ANALYZE
SELECT *
FROM service_zones
WHERE ST_Intersects(geom, ST_GeomFromText('POINT(127.0 37.5)', 4326))
AND deleted_at IS NULL;
-> Filter: (st_intersects(service_zones.geom, ...))
(cost=183 rows=33.5) (actual time=0.639..17.5 rows=2 loops=1)
-> Index range scan on service_zones using idx_geom ...
with index condition: st_keycheck(...)
(cost=183 rows=372) (actual time=0.0868..1.82 rows=303 loops=1)
Index range scan on service_zones using idx_geom을 보면, 공간 인덱스를 잘 타고 있는 걸 확인할 수 있습니다. 인덱스를 안 타서 느린 게 아니었어요. 인덱스를 타는데도 느린 겁니다. 그러면 왜?
아래쪽을 좀 더 자세히 보니 답이 보였습니다. 인덱스 스캔을 통해 가져온 후보군이 303개였거든요. 점 하나를 찍었을 뿐인데 후보가 303개라니. 그리고 이 303개의 후보 각각에 대해 실제 폴리곤과 점이 겹치는지 확인하는 PIP(Point-in-Polygon) 정밀 연산이 수행되면서 최종적으로 17.5ms까지 시간이 늘어나고 있었습니다. 최종 결과는 겨우 2개인데요.
인덱스는 제 역할을 하고 있었지만, 인덱스가 걸러준 후보군 자체가 너무 많은 게 문제였습니다. 왜 이렇게 많은 후보가 나오는지 이해하려면 MySQL의 공간 인덱스가 어떻게 작동하는지 알아야 합니다.
3. MBR과 공간 인덱스의 작동 방식
MBR(Minimum Bounding Rectangle)이란?
MySQL은 복잡한 다각형(Polygon)을 직접 인덱싱하지 않습니다. 대신 그 도형을 완전히 감싸는 최소 크기의 사각형(MBR)을 만들어 이를 R-Tree 구조로 관리합니다.
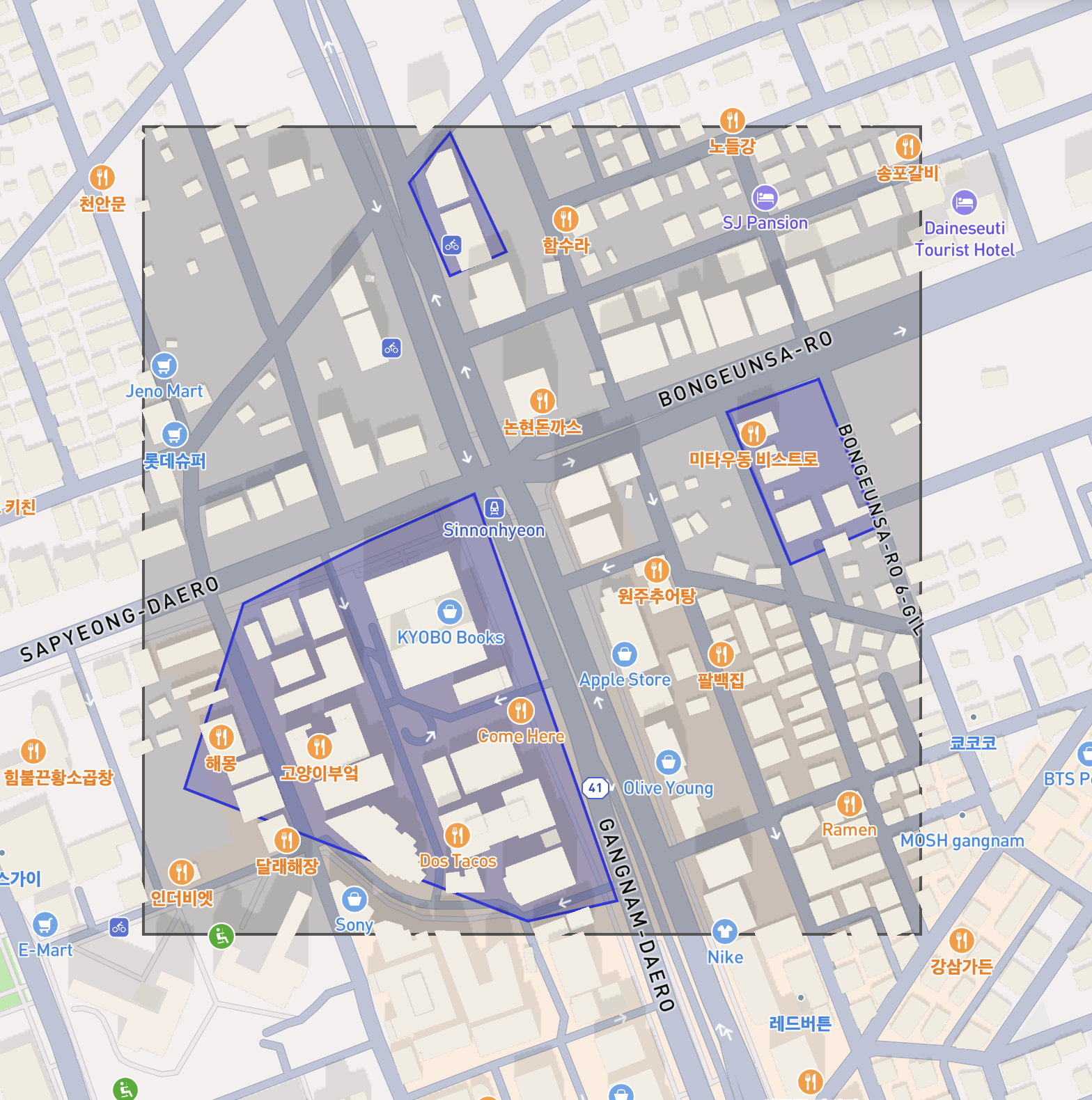
위 그림에서 파란색 영역이 실제 폴리곤 3개이고, 이걸 하나의 MultiPolygon으로 묶었을 때 생성되는 MBR이 검은색 사각형입니다. MySQL은 이 검은색 사각형을 인덱스에 저장합니다. 폴리곤이 흩어져 있을수록 MBR은 실제 도형보다 훨씬 넓어지게 되는 거죠.
공간 쿼리는 2단계로 처리됩니다:
- 1단계 (MBR 필터링): 쿼리 지점이 MBR 안에 포함되는지 인덱스에서 빠르게 거릅니다. 단순 사각형 비교라 가볍고 빠릅니다.
- 2단계 (PIP 연산): 1단계를 통과한 후보들을 대상으로, 실제 다각형의 경계선 안에 점이 있는지 정밀하게 계산합니다. 이 연산은 무겁습니다.
즉, MBR이 크면 클수록 1단계에서 걸러지지 않는 후보가 많아지고, 비싼 2단계 연산 횟수가 늘어나는 구조입니다.
MySQL 공간 인덱스의 제약
한 가지 더 알아둘 점이 있습니다. MySQL에서 공간 인덱스를 생성하려면 해당 컬럼이 반드시 NOT NULL이어야 합니다. 유효하지 않은 데이터라도 공간 데이터 타입의 ‘값’이 들어있어야 하고, 이게 인덱스 크기와 성능에 직접적으로 영향을 줍니다.
4. 범인은 ‘거대 MBR’과 ‘Soft-Delete’
조사 결과, 두 가지 원인이 겹쳐서 문제가 발생하고 있었습니다.
MultiPolygon의 함정: 거대 MBR 생성
데이터 생성 과정에서 전국에 산발적으로 흩어진 여러 폴리곤을 하나의 MultiPolygon으로 묶어 저장한 케이스가 있었습니다. 예를 들어 전국에 흩어진 여러 서비스 구역을 하나의 레코드로 묶어 관리한 경우인데요. 흩어진 영역들을 하나로 묶자, 대한민국 전체를 아우르는 거대한 MBR이 생성되어버렸습니다.
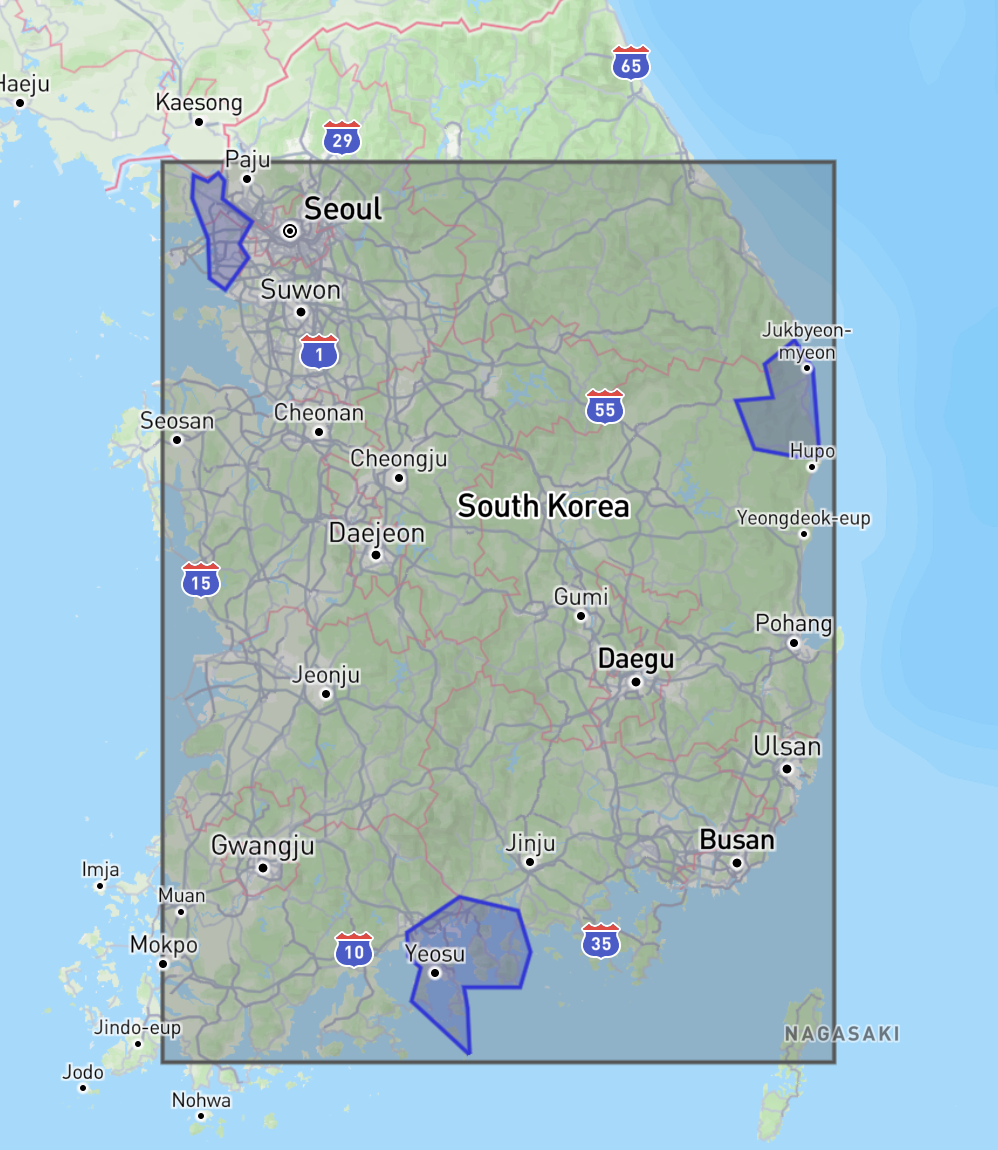
인천, 강원도, 여수 쪽에 각각 파란색 폴리곤이 하나씩 흩어져 있는데, 이걸 하나의 MultiPolygon으로 묶자 검은색 MBR이 대한민국 전체를 덮어버렸습니다. 이 상태에서는 전국 어디를 찍어도 이 MBR에 걸려서 후보군에 포함됩니다.
결과적으로 전국 어디를 찍어도 이 거대 MBR이 인덱스 검색 조건에 무조건 걸려들게 된 거죠.
Soft-Delete의 맹점
가장 치명적인 것은 이 데이터들이 deleted_at IS NOT NULL 상태인 Soft-deleted 데이터였다는 점입니다. 서비스 로직에서는 보이지 않지만, 공간 인덱스(R-Tree) 내에는 여전히 이 거대한 MBR들이 살아있었습니다.
MySQL 옵티마이저는 공간 인덱스를 먼저 탄 후 deleted_at을 나중에 필터링(Post-filtering)하기 때문에, DB 엔진은 매번 ‘유령 데이터’ 300여 개를 가져와 비싼 PIP 연산을 수행하고 있었던 겁니다.
정리하면:
- Soft-Delete된 데이터의 거대 MBR이 R-Tree에 남아 있음
- 어떤 좌표를 찍어도 이 MBR에 걸림
- 300개 넘는 후보에 대해 비싼 PIP 연산 수행
deleted_at IS NULL필터링은 그 이후에 발생- 결국 대부분이 버려지지만, 연산 비용은 이미 지불된 상태
5. 해결을 위한 두 가지 아이디어
이 문제를 해결하려면 R-Tree에서 불필요한 MBR을 없애야 합니다. 두 가지 접근법을 검토했습니다.
아이디어 1: 테이블 분리 (Archive Table)
삭제된 데이터를 별도의 아카이브 테이블로 옮기고, 라이브 테이블에서는 물리적으로 삭제(Hard Delete)하는 방식입니다. R-Tree에서 MBR이 완전히 제거됩니다.
- 장점: 인덱스에서 확실히 제거됨, 라이브 테이블이 가벼워짐
- 단점: 삭제 로직이 복잡해짐 (선 복사, 후 삭제)
아이디어 2: 고스트 데이터 처리 (Ghosting)
삭제 시 geom 데이터를 아주 작은 더미 폴리곤으로 교체하고, 실제 좌표는 unindexed_geom 컬럼에 보관하는 방식입니다. MBR이 극도로 작아지기 때문에 인덱스 검색에 거의 걸리지 않게 됩니다.
- 장점: 기존 테이블 구조 유지, 구현이 상대적으로 간단
- 단점: 라이브 테이블 부피가 줄어들지 않음, 공간 인덱스
NOT NULL제약 때문에 의미 없는 데이터가 계속 남음
저희는 인덱스 효율과 메모리 성능을 모두 챙기기 위해 아이디어 1(테이블 분리)을 선택했습니다. 라이브 테이블 자체를 가볍게 만드는 게 장기적으로 더 낫다고 판단했거든요.
6. 실전 적용: 테이블 분리를 통한 최적화
Phase 1. Archive 테이블 설계
이력을 보관하되, 원본의 id를 보존해서 추후 추적이 가능하도록 했습니다.
-- 라이브 테이블과 동일한 구조로 아카이브 테이블 생성
CREATE TABLE service_zones_archive LIKE service_zones;
-- auto_increment 제거 (원본 id를 그대로 보존하기 위해)
ALTER TABLE service_zones_archive MODIFY COLUMN id BIGINT NOT NULL;
-- 삭제 시점 기록용 컬럼 추가
ALTER TABLE service_zones_archive ADD COLUMN deleted_at DATETIME(6) DEFAULT CURRENT_TIMESTAMP(6);
Phase 2. 기존 Soft-Delete 데이터 이관
현재 deleted_at이 채워진 데이터들을 아카이브로 옮기고 라이브 테이블에서 물리적으로 삭제합니다.
-- 1. 삭제된 데이터를 아카이브로 복사
INSERT INTO service_zones_archive (...)
SELECT ... FROM service_zones WHERE deleted_at IS NOT NULL;
-- 2. 라이브 테이블에서 물리 삭제
DELETE FROM service_zones WHERE deleted_at IS NOT NULL;
이 과정을 거치면 R-Tree에서 거대 MBR들이 완전히 제거됩니다.
Phase 3. 애플리케이션 코드 수정
삭제 요청 시 기존의 UPDATE deleted_at = NOW() 대신 ‘선 복사, 후 삭제’를 수행하도록 로직을 변경했습니다.
// ArchiveZoneCascade: 삭제 전 데이터를 아카이브 테이블로 이관
func (r *serviceZoneRepository) ArchiveZoneCascade(
ctx context.Context,
dbHandler dbexec.Handler,
rootID int64,
) error {
// UNION ALL을 활용해 부모/자식 zone 데이터를 한 번에 아카이브 테이블로 INSERT
// ...
}
// deleteZoneCascade: 이관 확인 후 라이브 테이블에서 물리 삭제
func deleteZoneCascade(
ctx context.Context,
dbHandler dbexec.Handler,
repo *serviceZoneRepository,
zoneID int64,
batchSize int,
) error {
// 1. 먼저 아카이브 테이블로 복사
if err := repo.ArchiveZoneCascade(ctx, dbHandler, zoneID); err != nil {
return err
}
// 2. 복사 성공 후 라이브 테이블에서 물리 삭제
repo.DeleteByParentID(ctx, dbHandler, zoneID, batchSize)
repo.Delete(ctx, dbHandler, zoneID)
return nil
}
이렇게 하면 삭제된 데이터는 아카이브에만 남고, 라이브 테이블의 공간 인덱스에는 실제로 유효한 데이터만 존재하게 됩니다.
7. 왜 테이블 분리인가?
단순히 geom을 작은 값으로 바꾸는 것(아이디어 2)보다 테이블 분리가 유리한 이유는 명확합니다.
-
공간 인덱스 오버헤드 제거: 물리적 삭제만이 R-Tree에서 MBR을 완전히 제거할 수 있습니다.
deleted_at필터링은 인덱스 스캔 이후에 일어나기 때문에, Soft-Delete로는 근본적인 해결이 안 됩니다. -
메모리 효율 (InnoDB Buffer Pool): 삭제된 레코드가 사라지면 데이터 밀도가 높아집니다. 더 적은 수의 페이지로 쿼리를 처리할 수 있어 메모리 효율이 올라갑니다.
-
락 경합(Lock Contention) 감소: 공간 인덱스가 있는 테이블에서
UPDATE는 인덱스 재구성으로 인한 락 부하가 큽니다. Archive(Insert) + Delete 조합은 쓰기 부하를 분산시켜 동시성을 높여줍니다.
마무리
처음에 “인덱스를 타고 있는데 왜 느리지?”라는 의문에서 시작했는데, 결국 문제는 인덱스 자체가 아니라 인덱스 안에 들어있는 데이터의 품질이었습니다.
특히 공간 인덱스 환경에서 Soft-Delete가 얼마나 치명적일 수 있는지 직접 겪어보니 확 와닿더라고요. 일반 B-Tree 인덱스에서는 deleted_at 조건을 복합 인덱스에 포함시키는 것만으로 어느 정도 해결이 되지만, R-Tree는 구조 자체가 다르기 때문에 그런 우회가 통하지 않았거든요. 결국 데이터의 물리적 생명주기를 관리하는 것이 답이었습니다.
비슷한 이슈를 겪고 계시다면, 공간 인덱스에 ‘거대 MBR’ 유령이 살고 있지는 않은지 EXPLAIN ANALYZE로 확인해보시는 걸 추천합니다. 혹시 다른 방법으로 해결하신 분이 계시면 댓글로 공유해주시면 너무 좋을 것 같아요!
