
Redis는 왜 싱글 스레드일까?
Redis는 초기부터 싱글 스레드 모델로 설계되었습니다. 이는 단순히 “그냥 그렇게 만들었다”가 아니라, 명확한 설계 철학과 기술적 이유가 있었습니다.
✔ 이유 1 — 메모리 기반 DB라 CPU 연산이 빠름
Redis는 인메모리 데이터베이스입니다. 대부분의 작업이 메모리 연산이라 CPU 부하는 작고 I/O 대기 시간이 거의 없습니다.
# Redis의 대부분의 작업은 메모리 연산
SET key "value" # 메모리에 직접 쓰기
GET key # 메모리에서 직접 읽기
HGETALL hash # 메모리에서 해시 조회
이런 상황에서 멀티스레딩의 오버헤드(락, 컨텍스트 스위칭)가 실제 작업보다 더 비용이 컸습니다.
💡 CPU 연산이 빠르면 멀티스레딩의 오버헤드가 이점을 상쇄할 수 있습니다.
✔ 이유 2 — 락(lock) 필요 없음
싱글 스레드면 “동시에 쓰기”가 불가능합니다. 따라서 락이 필요 없습니다.
# 싱글 스레드 환경에서는 이런 상황이 불가능
Thread 1: SET key1 "value1" # 동시 실행 불가
Thread 2: SET key2 "value2" # 동시 실행 불가
이게 Redis의 “단순함 + 일관성 + 예측 가능한 성능”을 만든 핵심입니다.
- 단순함: 락 관리 로직이 필요 없음
- 일관성: 동시성 문제가 발생하지 않음
- 예측 가능한 성능: 컨텍스트 스위칭으로 인한 성능 저하가 없음
✔ 이유 3 — 병목은 CPU가 아니라 네트워크 I/O
초기의 Redis는 대부분의 시간을 네트워크 입출력에 사용했습니다.
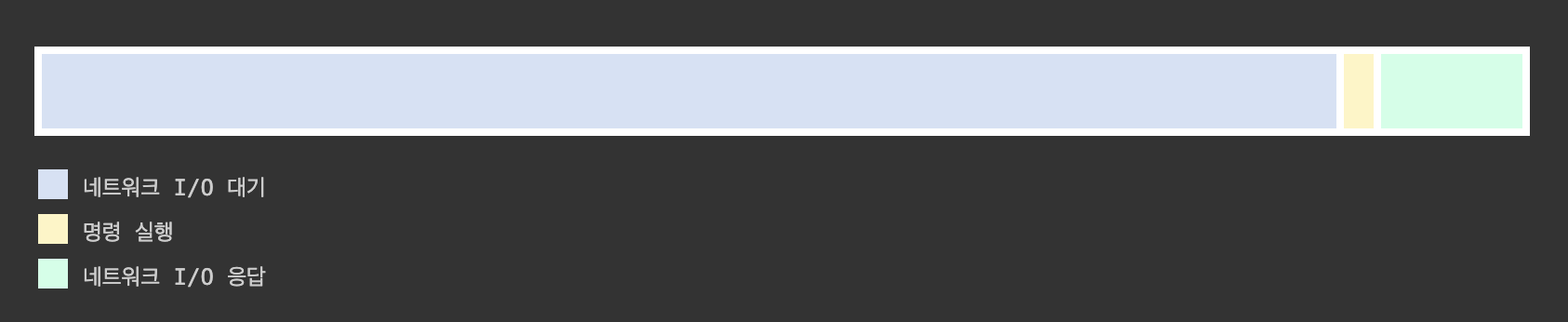
CPU를 여러 스레드로 나눌 이유가 없었던 이유는, 실제로 CPU가 바쁘지 않았기 때문입니다.
Redis는 정말 싱글 스레드인가?
사실 Redis도 6버전부터는 멀티스레드를 지원합니다. 하지만 이는 명령 실행을 멀티스레드로 처리한다는 의미가 아닙니다. 네트워크 I/O만 멀티스레드로 처리하며, 실제 명령 실행(SET, GET 등)은 여전히 싱글 스레드입니다.
✔ 이유: 네트워크가 CPU를 점점 많이 사용하게 됨
초기 Redis에서는 네트워크 I/O 대기 시간이 대부분이었습니다. 그러나 높은 요청량과 네트워크 처리 과정의 복잡도가 증가하면서, 네트워크 I/O 처리 과정에서 CPU 사용량이 병목이 되었습니다.
❓❓네트워크 I/O가 CPU를 사용한다?
네트워크 I/O는 디스크 I/O보다 훨씬 가벼워서 “비용이 거의 없다”고 오해하기 쉽습니다. 하지만 실제론 내부적으로 CPU 리소스를 많이 씁니다:
네트워크 I/O가 CPU를 사용하는 이유들:
- 소켓 버퍼 복사: 커널 버퍼 ↔ 유저 공간 버퍼 복사
- 커널 공간 ↔ 유저 공간 데이터 이동: 시스템 콜 오버헤드
- TLS 암복호화: AES, RSA 등 암호화 연산
- 패킷 조립/파싱: TCP/IP 스택 처리
- 프로토콜 처리: RESP(Redis Serialization Protocol) 파싱
- 높은 요청량(QPS): 초당 수만 건의 요청 처리
네트워크 패킷 수신
↓
커널 버퍼에 저장
↓
유저 공간으로 복사 (CPU 사용)
↓
프로토콜 파싱 (CPU 사용)
↓
명령 실행 (빠름)
↓
응답 직렬화 (CPU 사용)
↓
유저 공간에서 커널로 복사 (CPU 사용)
↓
네트워크로 전송
Redis 6의 변화
이런 이유로 네트워크 I/O가 CPU 병목으로 변했습니다:
예전: 네트워크 I/O 대기 시간 >> CPU 연산 시간
지금: 네트워크 처리 CPU 시간 >> 실제 명령 실행 시간
그래서 Redis 6부터 네트워크 I/O를 멀티스레드 처리하게 됩니다.
✔ 중요한 점: 네트워크 I/O 전용 멀티스레드
Redis 6부터 멀티스레드 지원은 “네트워크 I/O 전용 멀티스레드”입니다.
Redis 6+ 멀티스레드 구조:

실제 명령 실행(SET, GET, HGETALL 같은 데이터 처리)은 여전히 싱글 스레드입니다.
→ 즉, 병목이던 네트워크 부분만 제거한 것입니다.
싱글 스레드 Redis 사용 시 주의사항: KEYS 명령어
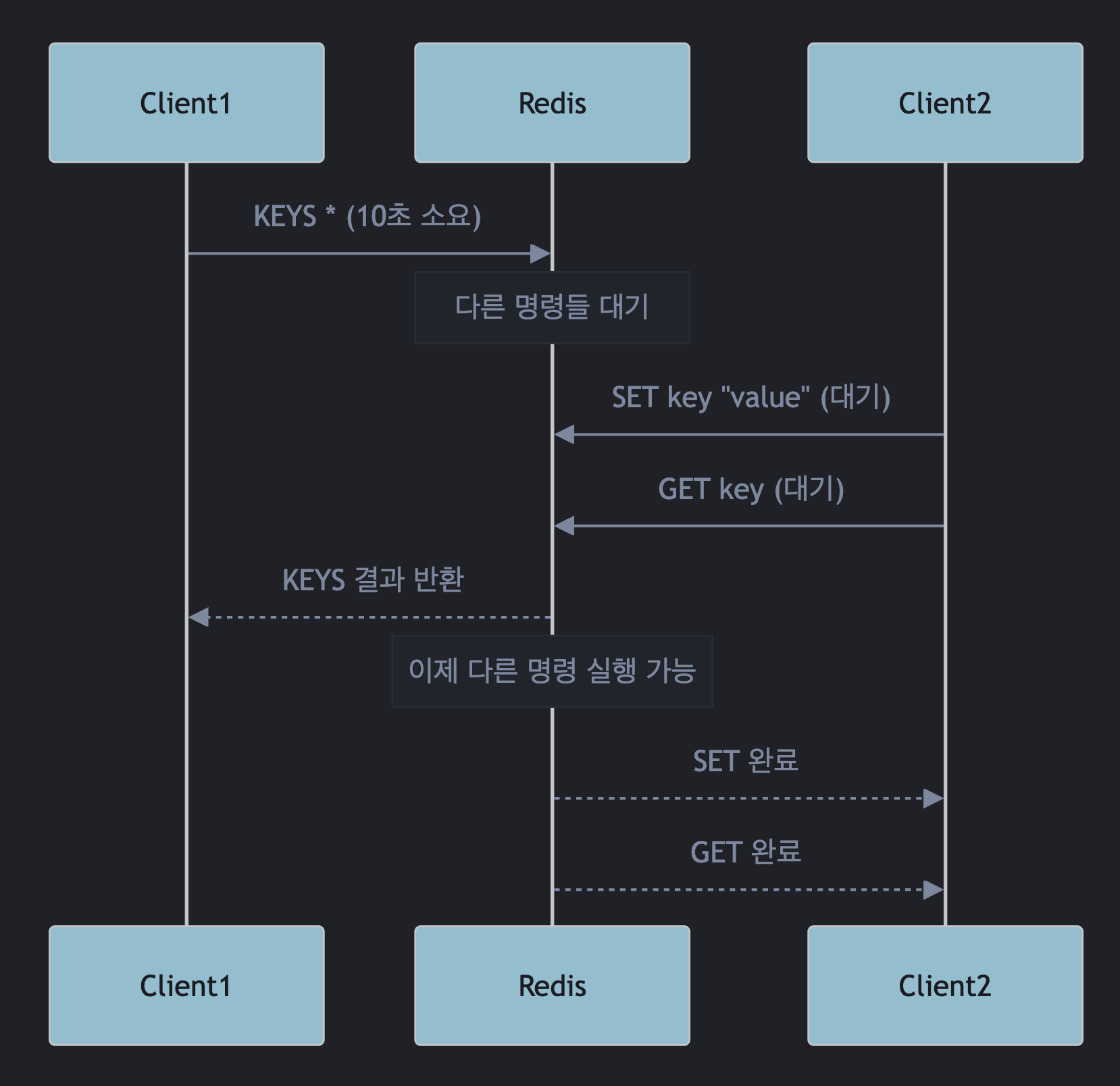
싱글 스레드로 동작하는 Redis를 사용할 때 주의해야 할 대표적인 사례가 있습니다. 바로 KEYS 명령어입니다.
KEYS 명령어의 문제점
KEYS 명령어는 전체 키 공간을 한 번에 훑는 O(N) 블로킹 명령입니다. Redis는 싱글 스레드이기 때문에, KEYS가 실행되는 동안 서버가 해당 명령에 완전히 점유됩니다.
# 모든 키를 한 번에 조회
KEYS *
# 패턴 매칭
KEYS user:*
만약 데이터가 굉장히 많다면, KEYS 명령이 완료될 때까지 다른 모든 명령이 대기하게 됩니다. 이는 서버가 멈춘 것과 같은 현상을 만들어냅니다.
Redis의 해결책: 이벤트 루프와 I/O 멀티플렉싱
싱글 스레드에서 블로킹만 하면 빠를 수 없었겠죠. 그래서 Redis는 이벤트 루프(Event Loop)와 I/O 멀티플렉싱(Multiplexing) 기법을 사용합니다.
간단히 이해하기
I/O 멀티플렉싱은 하나의 스레드가 여러 소켓 연결을 동시에 모니터링하고, 준비된 이벤트부터 처리하는 기법입니다. Redis는 이를 위해 epoll(Linux), kqueue(BSD/macOS), select(fallback) 같은 시스템 콜을 사용합니다.
이벤트 루프는 “대기 → 이벤트 발생 → 핸들러 실행 → 다시 대기”를 반복하는 구조입니다. 이렇게 하면 싱글 스레드에서도 여러 클라이언트의 요청을 효율적으로 처리할 수 있습니다.
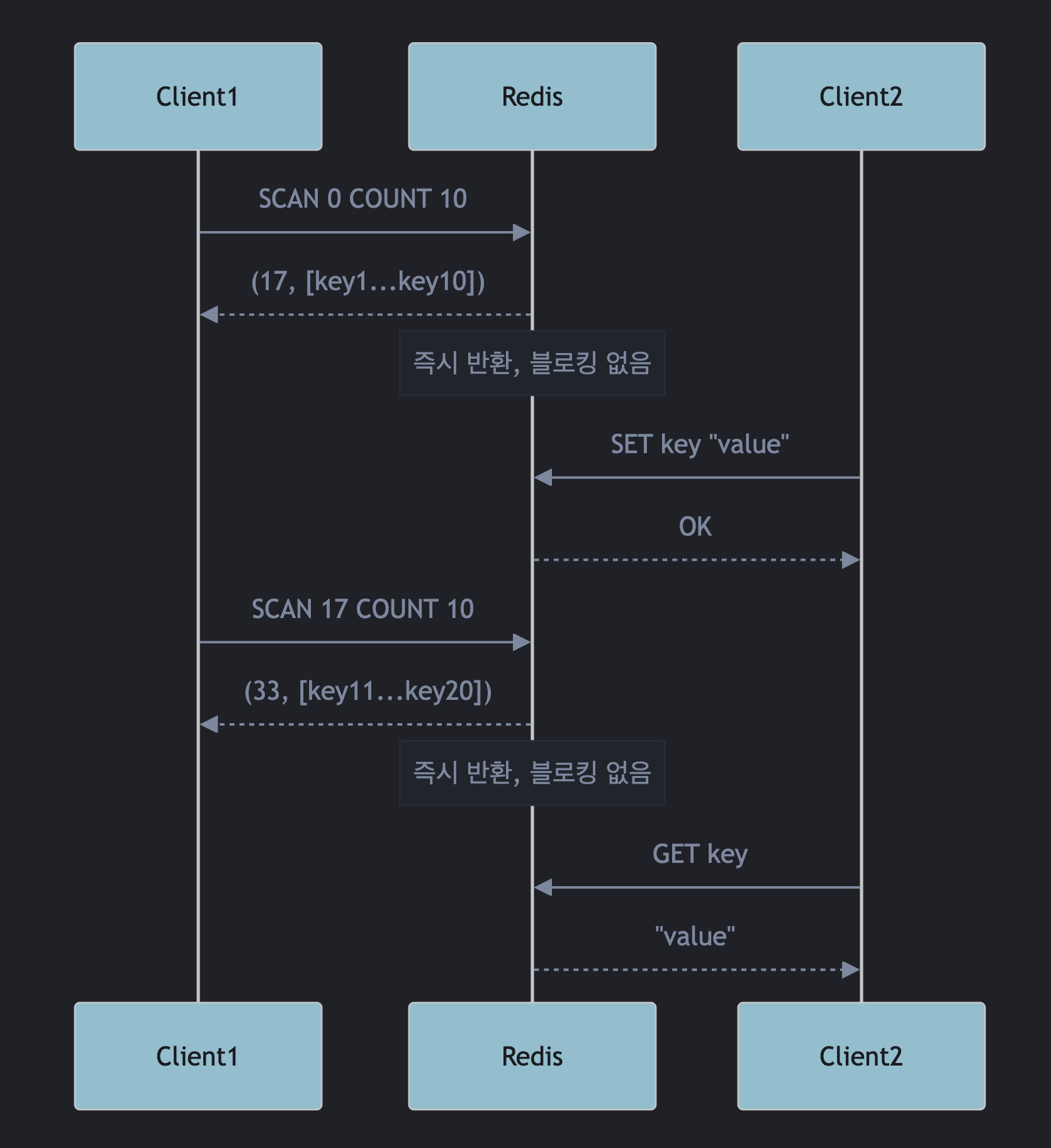
SCAN: KEYS의 대안
이 기법을 활용하는 것이 바로 SCAN 명령어입니다. SCAN은 전체 키를 한 번에 스캔하지 않고, 작은 조각(chunk) 단위로 나눠서 처리합니다.
# 첫 번째 스캔 (0은 시작 커서)
SCAN 0 COUNT 10
# 결과: (17, [key1, key2, ..., key10])
# ↑
# 다음 스캔에 사용할 커서 값
# 두 번째 스캔 (이전 호출에서 받은 커서 값 17 사용)
SCAN 17 COUNT 10
# 결과: (33, [key11, key12, ..., key20])
# ↑
# 다음 스캔에 사용할 커서 값
# 세 번째 스캔 (커서 값 33 사용)
SCAN 33 COUNT 10
# 결과: (0, [key21, key22, ..., key30])
# ↑
# 0이면 스캔 완료
SCAN은 작은 단위로 처리하고 즉시 반환하기 때문에, 이벤트 루프가 다른 명령도 함께 처리할 수 있습니다. 따라서 KEYS처럼 서버를 블로킹하지 않습니다.
Redis 공식 문서의 경고
Redis 공식 문서에서는 KEYS 명령어 사용에 대해 명확히 경고하고 있습니다:
Warning: consider
KEYSas a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout. Don’t useKEYSin your regular application code. If you’re looking for a way to find keys in a subset of your keyspace, consider usingSCANinstead.
마무리
Redis의 싱글 스레드 모델은 단순히 “그냥 그렇게 만들었다”가 아니라, 명확한 설계 철학과 기술적 이유가 있었습니다. 그리고 시간이 지나면서 병목이 바뀌었고, 그에 맞춰 Redis 6에서 네트워크 I/O만 멀티스레드로 처리하게 되었습니다.
하지만 여전히 명령 실행은 싱글 스레드입니다. 이는 Redis의 단순함과 일관성을 유지하기 위한 선택입니다.
만약 Redis를 사용하다가 속도가 느려진다면, 블로킹 명령어(KEYS, FLUSHALL 등)를 사용하고 있는지 확인해보세요. 또한 큰 데이터를 한 번에 처리하는 명령어나, 오래 걸리는 연산이 있는지 점검해보시기 바랍니다. Redis의 장점인 빠른 속도를 유지하려면, 싱글 스레드 환경에 맞는 사용법을 고려하는 것이 중요합니다!
